[Python] 비트코인 자동 매매 - 차트 불러오기
1. 차트 불러오기 전 자동 매매 과정을 글로 표현하면 아래와 같다. 시장 분석을 한다. 매수 / 매도 목표 가격을 정한다. 현재가를 확인한다. 매수 목표 이하의 가격일 경우 구매한다. 현재가를 확
chunws13.tistory.com
1. 머신러닝 패키지 설치
이전 글 기준으로 비트코인 가격을 가져와서 분석에 사용할 몇 가지 지표를 생성했다.
데이터를 가지고 머신러닝을 진행하기 앞서, 머신러닝을 사용하기 위한 패키지와 데이터 시각화를 위한 패키지를 설치하자
pip install scikit-learn #머신러닝 패키지
pip install matplotlib #시각화 패키지
2. 데이터 분류 하기
설치 이후, 학습을 위해 데이터를 두 과정을 먼저 거쳐야 한다.
1. 종속 변수와 독립 변수 선정
독립 변수와 종속 변수의 관계는, 독립 변수에 의해 종속 변수가 결정되는 관계이다.
차트 분석을 예로 들면, '이동평균 20일 데이터를 기준으로 당일 종가를 예측하겠다' 고 한다면
이동평균 20일 데이터는 독립 변수, 당일 종가는 종속 변수에 해당한다.
2. 학습 데이터와 테스트 데이터 분류
보유하고 있는 모든 데이터를 모두 학습시켜 모델을 만들면, 그 모델이 어느 정도의 성능을 보이는지 측정할 수 있는 데이터가 남지 않는다.
따라서, 머신 러닝 모델의 성능을 평가하기 위해 보유한 데이터를 학습 데이터와 테스트 데이터로 분류하는 작업이 필요하고,
학습 데이터로는 모델 학습을, 테스트 데이터로는 모델 성능 테스트를 진행한다.
위 내용을 코드로 표현하면 아래와 같다.
learning_data.dropna(inplace=True)
independent = learning_data[["open", "ma5", "ma20", "rsi", "volume7"]]
dependent = learning_data[["high", "low"]]
ind_train, ind_test, de_train, de_test = train_test_split(independent, dependent, test_size=0.2, random_state=40)시가, 이동평균 지수 (5일, 20일), rsi 지수와 최근 7일간의 거래량 기준으로 해당일 저가, 고가를 예측하기 위해 변수를 분류하였다.
독립 변수 : 시가, 이동평균 지수 (5일, 20일), rsi 지수, 초근 7일간의 거래량
종속 변수 : 당일 고가, 저가
또한, 학습과 테스트를 위해 데이터를 8:2로 분할한다. 해당 테스트는 독립 변수를 조정하며 사용했을 때
일관된 평가 기준을 세우기 위해 random_state를 지정한다.
해당 수치가 같다면, 동일한 배열의 데이터를 일정 비율로 나눈다고 해도 나눠지는 데이터는 같다.
3. 데이터 학습하고 평가하기
(ex. random_state가 40일 때, 1번 데이터가 테스트 데이터에 포함된다면, random_state 가 변하지 않는 한 항상 테스트 데이터로 분류)
model = LinearRegression()
model.fit(ind_train, de_train)
predict = model.predict(ind_test)
print(predict)그 후 회귀분석을 위한 모델을 만들고, 학습 데이터를 넣어 학습시킨 후, 테스트 데이터를 넣어 예측치를 확인한다.
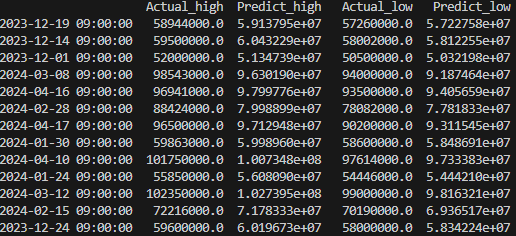
그렇다면 이 수치들이 실제와 얼마나 유사한지 확인하기 위해 Test 데이터의 실제 저가, 고가 / Predict 데이터의 저가, 고가를 비교해보자
result = pandas.DataFrame({
'Actual_high': de_test["high"],
"Predict_high": predict[:,0],
"Actual_low": de_test["low"],
"Predict_low": predict[:,1]})
print(result)
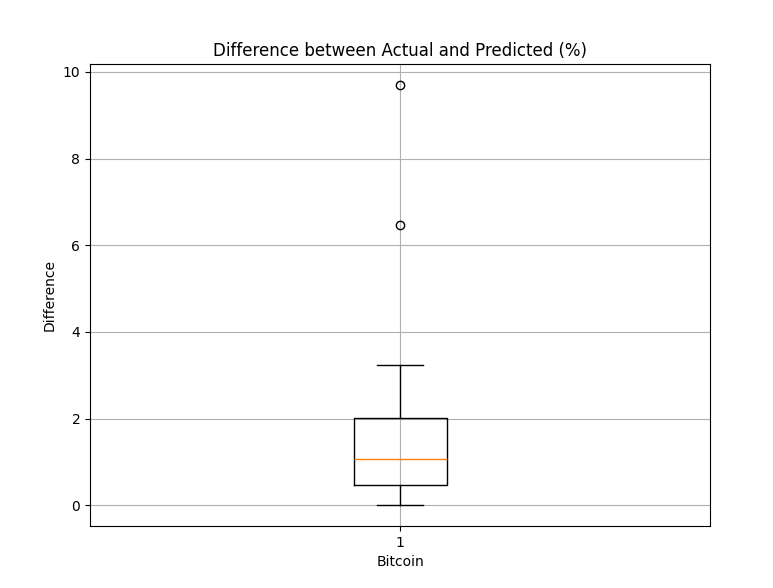
위 수치만 가지고 어느정도 성능을 보이는지 파악이 잘 안되는 것 같으니, box plot으로 데이터를 시각화 해보자
result["diff_number"] = result["Predict_high"] - result["Actual_high"]
result["diff"] = abs(result["Predict_high"] - result["Actual_high"]) / result["Actual_high"] * 100
plt.figure(figsize=(8, 6))
plt.boxplot(result["diff"])
plt.title('Difference between Actual and Predicted (%)')
plt.xlabel('Bitcoin')
plt.ylabel('Difference')
plt.grid(True)
plt.show()고가를 기준으로 예측된 고가가 실제 고가 대비 어느정도 비율의 차이가 있는지를 확인한다.

결측치를 제외하면 최대 2.3% 더 높게 예측했고, 최소 0.01 높게 예측한 것으로 볼 수 있으며 중위값 기준 약 1% 더 높게 예측했다.
저가 예측은 위의 코드에서 이름만 바꾸면 바로 볼 수 있다.
저가 예측의 경우, 고가 대비 box plot 범위가 더 넓은 모습을 보이고 있다.
해당 수치로 실제 투자에 적용하기에는 무리가 있다고 판단하는 경우, 독립 변수를 조정하며 테스트 결과를 확인하면 된다.
하지만 너무 정확한 수치에 집착하다 보면, 과거 데이터에 과적합한 모델로 미래 데이터를 예측 할 수 있으므로 주의가 필요하다.
4. 전체 코드
def regression_test(learning_data): # 모델 테스트
learning_data.dropna(inplace=True)
independent = learning_data[["open", "ma5", "ma20", "rsi", "volume7"]]
dependent = learning_data[["high", "low"]]
ind_train, ind_test, de_train, de_test = train_test_split(independent, dependent, test_size=0.2, random_state=40)
model = LinearRegression()
model.fit(ind_train, de_train)
predict = model.predict(ind_test)
print(predict) # 데이터 출력
result = pandas.DataFrame({'Actual_high': de_test["high"], "Predict_high": predict[:,0], "Actual_low": de_test["low"], "Predict_low": predict[:,1]})
print(result) # 데이터 출력
result["diff_number"] = result["Predict_high"] - result["Actual_high"]
result["diff"] = abs(result["Predict_high"] - result["Actual_high"]) / result["Actual_high"] * 100
plt.figure(figsize=(8, 6))
plt.boxplot(result["diff"])
plt.title('Difference between Actual and Predicted (%)')
plt.xlabel('Bitcoin')
plt.ylabel('Difference')
plt.grid(True)
plt.show()다음 글에서는 코인 별로 고가, 저가를 예측한 데이터를 토대로 투자 대상 코인을 선별하는 과정을 알아보자
다음 글 - 투자 대상 코인 선정하기
'Backend > Python' 카테고리의 다른 글
| [Python] 비트코인 자동매매 - 백테스팅 (0) | 2024.05.15 |
|---|---|
| [Python] 비트코인 자동매매 - 종목 선정 (0) | 2024.05.09 |
| [Python] 비트코인 자동 매매 - 차트 불러오기 (0) | 2024.04.16 |
| [Python] 비트코인 자동 매매 - 준비 (0) | 2024.04.13 |
| [FastAPI] File Upload 구현하기 (0) | 2024.02.14 |

